DIFFUSION ADVERSARIAL REPRESENTATION LEARNING FOR SELF-SUPERVISED VESSEL SEGMENTATION
スポンサーリンク
論文URL
https://arxiv.org/abs/2209.14566 2022年9月公開


ポイント
- 自己教師あり学習で血管セグメンテーション
- 冠動脈造影X線画像と網膜画像で評価
- どちらも二次元画像
- モデルの学習は冠動脈造影X線画像で行い、その学習済みモデルで網膜画像の血管セグメンテーションも行っていた
- 造影X線画像から血管領域セグメンテーションを行うパスAと、血管が写っていない非造影X線画像(背景画像)と血管構造を模擬したフラクタル画像から疑似造影X線画像を生成するパスBを用意
- パスAとBでほぼモデルを共有
- GeneratorのSwitchable SPADE (spatially-adaptive denormalization layer)だけパスA、Bで動きが変わる
- パスAではInstance Normalizationとして働き、パスBではフラクタルマスクを入力条件としたSPADEブロックとして働く
- GeneratorのSwitchable SPADE (spatially-adaptive denormalization layer)だけパスA、Bで動きが変わる
- 網膜画像に対してもそのまま使えているのは凄いと思う一方、背景画像がないと学習できないことは実用上厳しいと感じる。
- パスAとBでほぼモデルを共有
- パスA、パスBの出力をCycle GANの枠組みで学習
- パスBを先に通し生成された疑似造影画像をパスAに通す。パスAで生成した血管マスクがパスBの入力に用意したフラクタル画像と一致するようにConsistencyを取る。
- パスA,BともにGeneratorに通す前に拡散モデルに通す
- 拡散モデルは血管が写っていないパスBの非造影X線画像で学習するのがポイント
- パスAで拡散モデルにかけると血管領域が拡散モデルが推定する潜在空間でoutlierになるため、Generatorが血管マスクを推定する際の良い特徴量になる
- 拡散モデルを挟むことで入力ノイズに対してロバストになる
- 推論時は入力画像に1ステップ分だけノイズを乗せ、逆拡散過程も1回だけ行うケースが最も性能が高くなっていた
- 逆拡散過程を繰り返す必要がないため、通常の拡散モデルほどは推論が遅くならない
- 拡散モデルは血管が写っていないパスBの非造影X線画像で学習するのがポイント
- 冠動脈造影X線画像と網膜画像で評価
スポンサーリンク
Striking the Right Balance with uncertainty
スポンサーリンク
論文URL
ポイント
- クラスレベルとサンプルレベルの分類の不確定性を考慮して、マージンを最大化するLossを提案
- 以下のSlide Shareを見ると分かりやすい
- 【CVPR 2019】Striking the Right Balance with Uncertainty
www.slideshare.net
スポンサーリンク
Deep Learning for Chest Radiograph Diagnosis in the Emergency Department
スポンサーリンク
論文URL
https://pubs.rsna.org/doi/10.1148/radiol.2019191225 2021年8月公開
ポイント
- Lunitの胸部レントゲン画像用AIを救急での使用を想定して評価
- 1施設のみ
- 後ろ向き試験






スポンサーリンク
Bounding Box Regression with Uncertainty for Accurate Object Detection









Precise diagnosis of intracranial hemorrhage and subtypes using a three-dimensional joint convolutional and recurrent neural network
スポンサーリンク
論文URL
https://link.springer.com/article/10.1007%2Fs00330-019-06163-2 2019年4月公開
ポイント
- CT画像により脳出血の分類
- 1検査単位での検出とスライス単位での検出の両方に対応
- VGG16のFC層で各スライスに対し抽出した特徴量ベクトルを双方向GRUにかけ分類
- HU範囲別の3チャンネル化
- -50~150:正常部位と出血部位の判別
- 100~300:頭蓋内と骨の間のHU値変化にフォーカス
- 250~450:骨にフォーカス
- 1検査単位の場合はスライスごとに出力される特徴量ベクトルをAverage Poolingしている
- HU範囲別の3チャンネル化
- 出血の有無を分類するモデルと、出血の種類を分類するモデルを分けている


 Supplementary Figure 1
Supplementary Figure 1




スポンサーリンク
Probabilistic End-to-end Noise Correction for Learning with Noisy Labels
スポンサーリンク
論文URL
ポイント
- ラベルのアノテーションミスを推定し、修正したラベルにより分類モデルを学習するPENCIL(probabilistic end-to-end noise correction in labels)フレームワークを提案
- 数十%の大量のミスラベルが有っても一定の性能を確保している
- 精度の高いラベルが付いたデータセットも不要
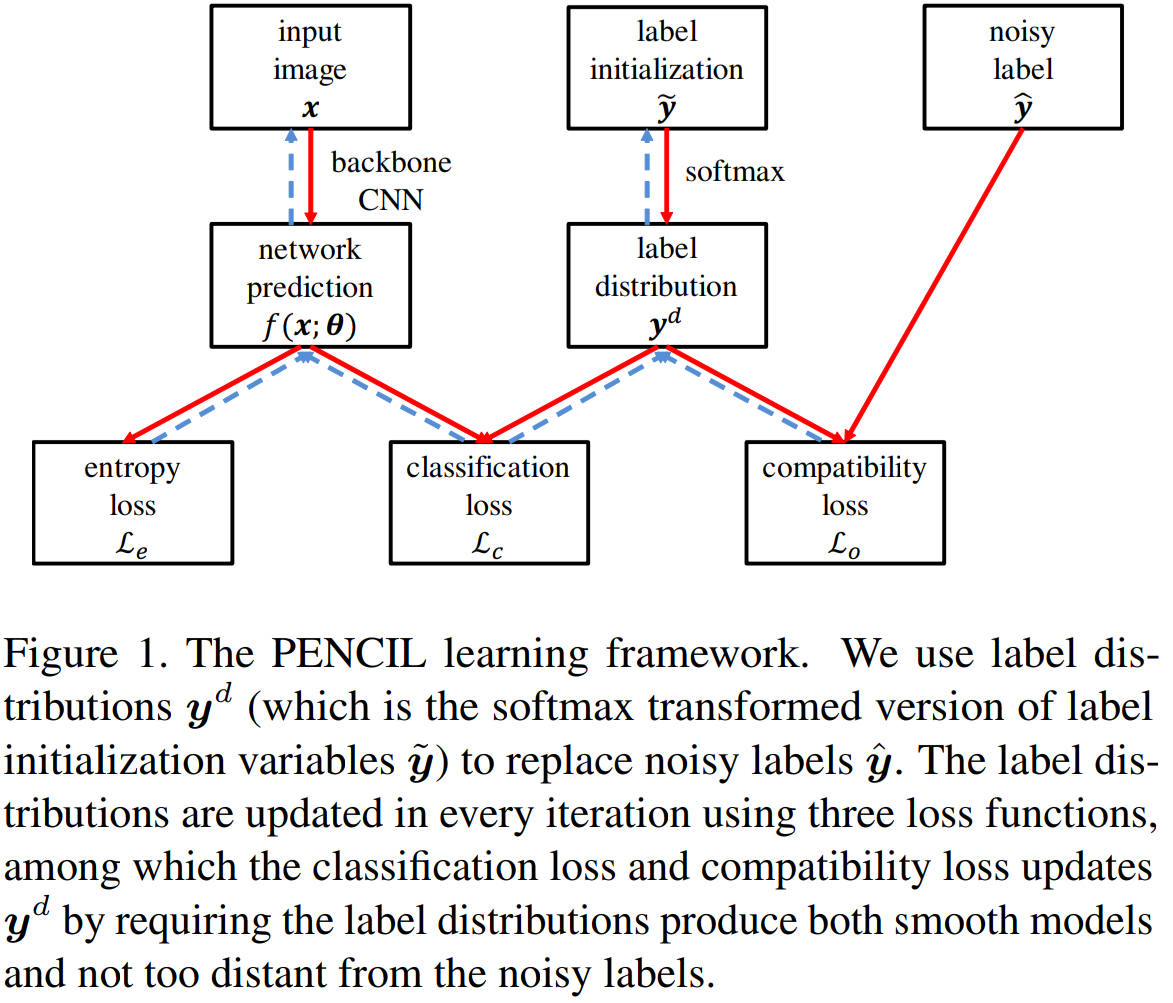
- Entropy Loss

- このLossによりone-hot distributionを保てるとのこと
- Classification Loss

- 基準の分布を教師ラベルではなく、推論確率にしている
- Compatibility Loss

- 最初のラベルと修正後のラベルが変わりすぎないように抑制するLoss
- 学習方法



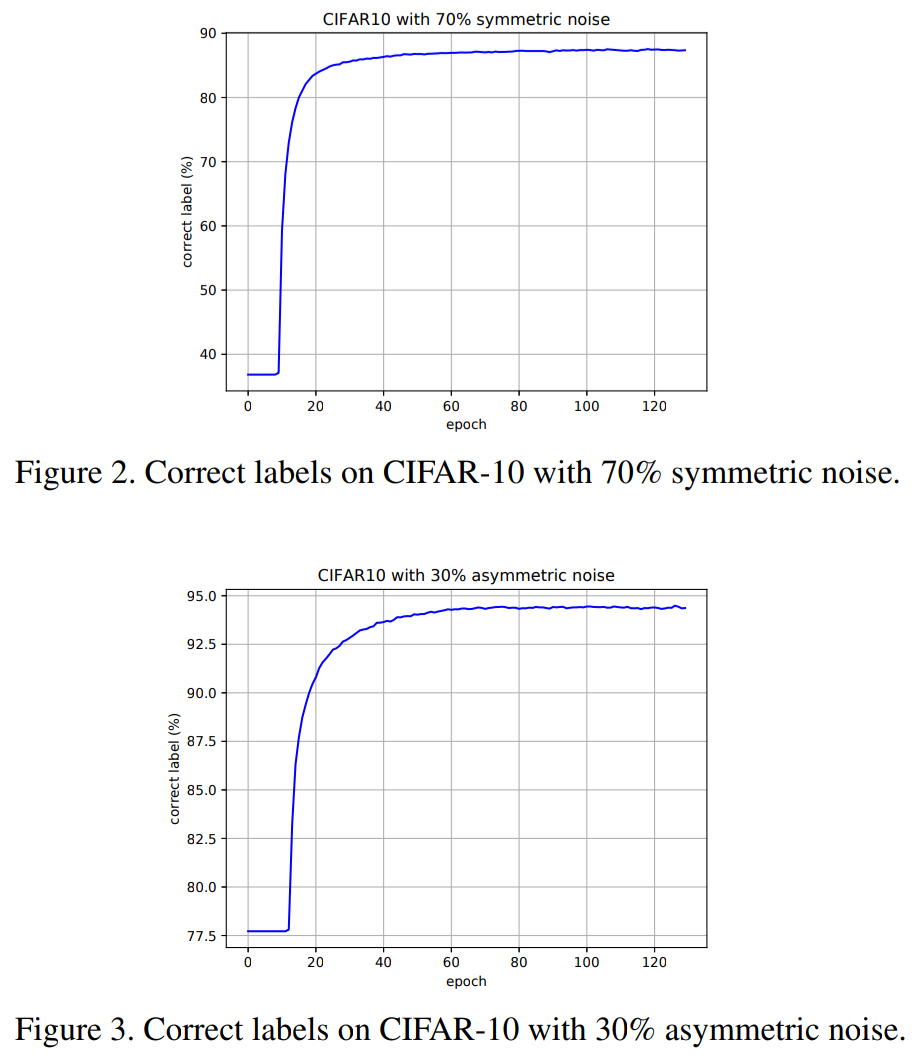

- CUB-200は鳥の分類データセットで高精度のラベルが付いていると考えられている
- ラベルが高精度でもPENCILが悪さをすることはなく、ハイパーパラメータ次第では高精度になることも。
スポンサーリンク
SSAP: Single-Shot Instance Segmentation With Affinity Pyramid
スポンサーリンク
論文URL
https://arxiv.org/pdf/1909.01616.pdf 2019年9月公開
ポイント
- proposal-free instance segmentation
- 先にセグメンテーションを行い、セグメンテーション結果および画素間の類似度に基づき物体を分ける

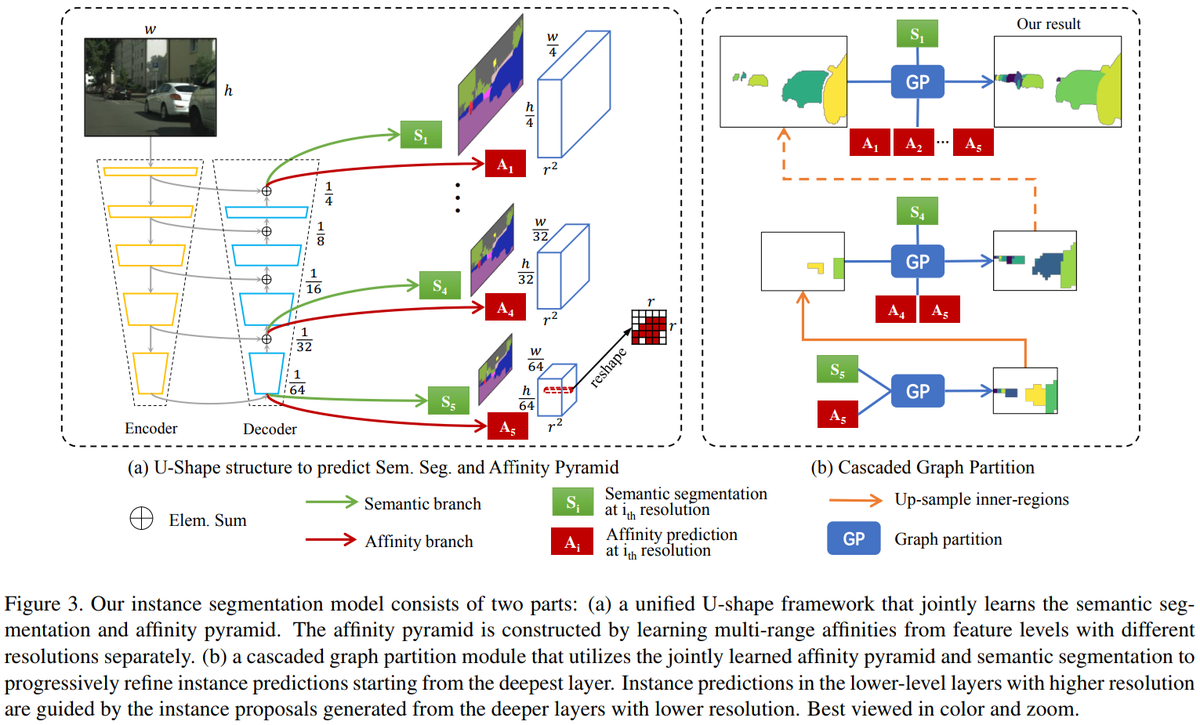

- 5x5の範囲で当該領域の中心画素と周囲画素の類似度(Affinity)を推定
- 各解像度のレイヤーで常に5x5の範囲を計算することで、大域特徴量と局所特徴量を取得している
- あまり理解できていないが、Graph Partitionを低解像度側から行うことで、計算時間やメモリの削減につながっている
- 低解像度側でクラスタ化された領域は高解像度側では計算対象外となっている?

スポンサーリンク